 मिसळपाव
मिसळपाव
एकदा माझ्या मोठ्या मुलाला शाळेत मांसाहारी फुलाबद्दल (व्हिनस फ्लायट्रॅप) माहिती दिली होती पण त्याचे जे फोटो दाखवले ते ब्लॅक अॅन्ड व्हाइट होते. रंगीत फोटोसाठी तो माझ्यामागे लागला होता. त्याला फक्त फोटो बघायचे होते. मग त्याला मी म्हटले गुगल वर शोधुयात ना! गुगलच्या चित्रविभागाला साकडे घालून त्या फुलाची आणि त्यासारख्या दुसर्या फुलांचीही चित्रे त्याला दाखवून गुगलच्या शोध जगताची अलीबाबाची गुहा त्याला उघडून देली. काहीही शोधायचे असल्यास गुगल मध्ये सर्च करून माहिती मिळवता येते, ह्या कल्पनेने तो एकदम खुष झाला. मग त्याचे आणि माझे 'गुगल शोध' बद्दल झालेले बोलणे त्याने माझ्या धाकट्या मुलालाही सांगितले, प्रात्यक्षिकासहित. त्याचे त्यालाही कौतुक वाटून त्याचीही उत्सुकता चाळवली गेली.
'बाबा, गुगलवर आपण काहीपण शोधू शकतो?', गाल फुगवून आणि डोळे मोठ्ठे करून धाकट्याने विचारले. मी एकदम टेक सॅव्ही बाप असल्याच्या कौतुकाने त्याला म्हणालो, 'हो काहीपण, तुला काय शोधायचे ते सांग आपण शोधूया'. एकदम निरागसतेने त्याने विचारले, 'आई चिडल्यावर कधी-कधी तुम्ही म्हणता ना मला की नविन आई आणूयात! ही नविन आई पण आपण गुगलवर शोधू शकतो का?". च्यायला, ही आत्ताची लहान पिढी आपलेच दात आपल्या घशात कसे घालील ह्याचा काही नेम नाही. पण वेळ बरी होती, अर्धांग स्वयंपाकघरात गुंतलेले होते. मी लगेच, 'अरे चला तुम्हाला आइसक्रीम खायचे होते ना, जाऊया', असे म्हणून वेळ मारून नेण्यासाठी त्यांना घेऊन बाहेर पडलो. आईसक्रीमच्या खुषीत धाकटा त्याचा प्रश्न विसरून गेला. पण मोठ्या मुलाने, गुगलकडे ही सगळी माहिती अशी असते, तो ही सगळी माहिती आपल्याला अशी काय दाखवू शकतो असे 'समंजस' प्रश्न विचारले. त्याला समजावून देता देता लक्षात आले की 'एंटरप्राईज सर्च' ह्या क्षेत्रात काम केल्यामुळे माहिती झालेल्या ह्यातल्या तांत्रिक बाबींची माहिती साध्या आणि सोप्या भाषेत सर्वांनाच करू देता येईल. चला तर मग बघुयात हे सर्च इंजीन कसे काम करते ते...
आजच्या ऑनलाईन जगात इंटरनेट हे माहितीचे भांडार झाले आहे. सर्व लहान मोठ्या कंपन्या त्यांचे ब्रॅन्ड्स, त्यांची उत्पादने आणि सेवा ह्यांच्या माहितीसाठी आणि मार्केटींगसाठी इंटरनेटचा प्रभावी वापर करुन त्या भांडारात भर टाकत आहेत. वेब २.० ( Web 2.0 ) मुळे इंटरनेट वाचनीय न रहाता लेखनीयही झाले आहे. लाखो ब्लॉगर्स विवीध विषयांवर लेखन करून त्या भांडाराला दिवसेंदिवस समृद्ध करीत आहेत. ही सर्व माहिती, अफाट पसरलेल्या आणि गहन खोली असलेल्या महासागराप्रमाणे आहे. आता ह्या माहितीच्या अफाट सागरातून आपल्याला हवी असलेली नेमकी माहिती शोधायची म्हणजे अक्षरशः 'दर्या मे खसखस' शोधण्यासारखेच आहे. इथेच हे इंटरनेट सर्च इंजीन अल्लादिनच्या जादूच्या दिव्यातील जिनप्रमाणे आपल्या मदतीसाठी पुढे येते.
ही मदत करण्यासाठी इंटरनेट सर्च इंजीन अविरत कार्यरत असते. ह्या कामाची विभागणी खालील तीन मुलभूत प्रकारांत केलेली असते.
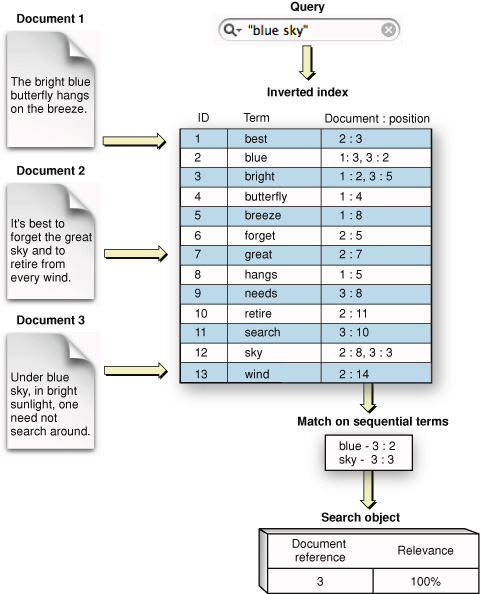
 सर्च इंजीनच्या सूचीत नॉर्मलाईझ केलेले शब्दांचे मूळ रूप आणि ते कोण कोणत्या वेब पेजेस वर आले आहे त्यांची यादी असते. हेही फक्त वानगीदाखल आहे. हे सूचीकरण हा तर सर्च इंजीनचा आत्मा असतो आणि ते त्यांचे व्यावसायिक सिक्रेट असते. ह्या सूचीवरच सर्व डोलारा उभा असतो. ह्या सूचीला तांत्रिक भाषेत 'Inverted index' म्हणतात.
सर्च इंजीनच्या सूचीत नॉर्मलाईझ केलेले शब्दांचे मूळ रूप आणि ते कोण कोणत्या वेब पेजेस वर आले आहे त्यांची यादी असते. हेही फक्त वानगीदाखल आहे. हे सूचीकरण हा तर सर्च इंजीनचा आत्मा असतो आणि ते त्यांचे व्यावसायिक सिक्रेट असते. ह्या सूचीवरच सर्व डोलारा उभा असतो. ह्या सूचीला तांत्रिक भाषेत 'Inverted index' म्हणतात.
 ह्या सूचीत तो शब्द त्या वेब पेज वर किती वेळा आला आहे, कुठे आला आहे, कुठल्या महत्वाच्या टॅग्स मध्ये आला आहे अशी विवीध माहिती असते. ह्या सूचीची रचना, सर्च इंजीन शोध निकाल किती जलद देऊ शकत ह्यासाठी फारच महत्वाची असते.
ह्या सूचीत तो शब्द त्या वेब पेज वर किती वेळा आला आहे, कुठे आला आहे, कुठल्या महत्वाच्या टॅग्स मध्ये आला आहे अशी विवीध माहिती असते. ह्या सूचीची रचना, सर्च इंजीन शोध निकाल किती जलद देऊ शकत ह्यासाठी फारच महत्वाची असते.
 (सर्व चित्रे आंतरजालावरून साभार)
(सर्व चित्रे आंतरजालावरून साभार)
| १ | माग काढणे (Web Crawling) | इंटरनेटवरील सर्व वेब पेजेसचा माग काढून, त्यांना भेट देऊन त्यावरील माहिती गोळा करणे |
| २ | पृथ:करण आणि सूची करणे (Analysis & Indexing) | गोळा केलेल्या माहितीचे पृथ:करण (Analysis) आणि सुसुत्रीकरण (Alignment) करून त्या माहितीचा जलद शोध घेण्यासाठी सूची (Index) बनवणे |
| ३ | शोध निकाल (Search Result) | शोध घेणार्या इंटरनेट वापरकर्त्यांना (Users) सूची वापरुन योग्य तो शोध निकाल (Search Result) कमीत कमी वेळात दाखवणे |
१. Web Crawling (माग काढणे)
आपल्याला हवी असलेली माहिती इंटरनेटवर नेमक्या कोणत्या पानावर आहे हे आपल्याला सांगण्याआधी ते पान इंटरनेट सर्च इंजीनला माहिती असले पाहिजे, हो ना? त्यासाठी सर्च इंजीनला अस्तित्वात असलेल्या सर्व वेब पेजेसचा मागोवा घ्यावा लागतो. रोज भर पडण्यार्या ह्या करोडो वेब पेजेसना भेट देऊन त्यांचा मागोवा घेणे हे काही खायचे काम नाही (ह्या खडतर कामाचा आवाका, मुलींचा मागोवा घेत फिरणार्यांना नक्की ध्यानात येईल ;) ). ह्यासाठी सर्च इंजीन्स, सोफ्ट्वेअर रोबोट्स वापरतात ज्यांना 'स्पायडर (Spider)' म्हटले जाते. हे स्पायडर्स अक्षरशः इंटरनेटभर सरपटत जाउन ही माहिती गोळा करतात म्हणून ह्या प्रक्रियेला Web Crawling म्हणतात. ही प्रक्रिया पुनरावर्तन (Recursion) प्रक्रिया असते म्हणजे सुरुवातीच्या, पहिल्या पानावर असलेल्या सर्व लिंक्स गोळा केल्या जातात आणि मग त्या प्रत्येक लि़कला भेट देऊन पुन्हा त्या पानावरच्या सर्व लि़क गोळा करून त्या प्रत्येक लिंकला भेट देत ह्याची आवर्तने होत राहतात. आता कळीचा मुद्दा हा आहे की ह्या प्रत्येक पानाला भेट दिल्यावर काय माहिती गोळा केली जाते? प्रामुख्याने सर्व स्पायडर्स 'मजकूर स्वरूपातली (Text)' माहिती गोळा करतात. प्रत्येक सर्च इंजीन्सची आपापली विशीष्ट अशी अल्गोरिदम्स असतात ही माहिती गोळा करण्यासाठी. पण प्रामुख्याने वेब पेजचे टायटल, मेटा टॅग्स, हेडर टॅग्स, चित्रांना दिलेला मजकूर (Alt tag) ह्यांत असलेल्या Text ला जास्त वेटेज दिले जाते. कारण हा मजकूर त्या वेब पेजला 'डिफाईन' करत असतो. त्यानंतर Body tag मधला मजकूर गोळा केला जातो. काही वेब साइट्सना काही पेजेसचा मागोवा घेऊ द्यायचा नसतो. अशा वेळी ह्या साइट्स Robots.txt नावाची फाईल त्यांच्या साइट्वर ठेवतात. ही फाइल म्हणजे स्पायडर्स आणि वेब साइट ह्यांच्यामधला करार (Robots Exclusion Protocol) असतो. ज्या वेब पेजेसना ह्या स्पायडर्सनी भेट देऊ नये असे ठरवले असते त्या वेब पेजेसची नावे (लिंक्स) ह्या फाइलमध्ये लिहीलेली असतात. स्पायडर्स Crawling किंवा पुनरावर्तन चालू करायच्या आधि ही फाइल वाचून त्याप्रमाणे लिंक्स मागोवा घेताना गाळतात.२. Analysis & Indexing (पृथ:करण आणी सूचीकरण)
ही सगळी 'मजकुर (Text)' माहिती गोळा करून सर्च इंजिन्स त्यांच्या जवळ ठेवत नाहीत. त्या माहितीचे पृथ:करण करून त्यातली शोध घेण्याच्या कामी येणारी माहितीच फक्त वापरली जाते. पण हे पृथ:करण असते तरी काय? पृथ:करण ह्यात प्रथम जी माहिती गोळा केली आहे ती कोणत्या भाषेतली आहे ते तपसले जाते. त्या भाषेच्या अनुषंगाने पृथ:करण कार्यवाहक (Analysers) वापरले जातात. एकदा भाषा कळली की मग त्या Text चे प्रसामान्यीकरण (Normalization) केले जाते. ह्यासाठी वापरली जाणारी प्रोसेस 'Stemming किंवा Lemmatization' म्हणून ओळखली जाते. ह्यात शब्दांची विवीध रूपे (धातूसाधित रूपे) त्यांच्या मूळ (धातू) प्रकारात आणली जातात. ह्म्म.. जरा बोजड झाले ना, वोक्के, उदाहरण बघू म्हणजे समजेल. car, cars, car's, cars' ह्याचे मूळ रूप car हे घेतले जाते. त्यामुळे जेव्हा 'car' हा शब्द सर्च टर्म म्हणून वापरला जाईल तेव्हा car चे कोणतेही रुप असलेली वेब पेजेस शोधली जातील. अजून एक उदाहरण बघुयात, "the boy's cars are different colors" वे वाक्य "the boy car differ color" असे Normalize केले जाईल. हे फक्त वानगीदाखल आहे. प्रत्यक्षात बरीच वेगवेगळी अल्गोरिदम्स वापरली जातात आणि ही प्रोसेस खुपच क्लिष्ट आहे. सूचीकरण आता ह्या नॉर्मलाईझ केलेल्या शब्दांच्या मूळ रुपांना (धातूंना) सूचीबद्ध केले जाते. ही सूची (फक्त समजण्यासाठी) पुस्तकाच्या शेवटी जी सूची (Index) असते, म्हणजे शब्दांची यादी आणि तो शब्द पुस्तकात कोण-कोणत्या पानांवर आलेला आहे ते पृष्ठ क्रमांक, साधारण तशीच, त्या प्रकारची एक सूची असते.
सर्च इंजीनच्या सूचीत नॉर्मलाईझ केलेले शब्दांचे मूळ रूप आणि ते कोण कोणत्या वेब पेजेस वर आले आहे त्यांची यादी असते. हेही फक्त वानगीदाखल आहे. हे सूचीकरण हा तर सर्च इंजीनचा आत्मा असतो आणि ते त्यांचे व्यावसायिक सिक्रेट असते. ह्या सूचीवरच सर्व डोलारा उभा असतो. ह्या सूचीला तांत्रिक भाषेत 'Inverted index' म्हणतात.
ह्या सूचीत तो शब्द त्या वेब पेज वर किती वेळा आला आहे, कुठे आला आहे, कुठल्या महत्वाच्या टॅग्स मध्ये आला आहे अशी विवीध माहिती असते. ह्या सूचीची रचना, सर्च इंजीन शोध निकाल किती जलद देऊ शकत ह्यासाठी फारच महत्वाची असते.
३. Search Result (शोध निकाल)
जेव्हा शोधकर्ता काही शोधण्यासाठी इंटरनेट सर्च इंजीन वापरतो तेव्हा जे शोधायचेय त्याच्यापेक्षा भलतीच काही वेब पेजेस शोध निकालात दिसली तर शोधकर्ता पुन्हा ते सर्च इंजीन वापरणारच नाही आणि तो असंतुष्ट वापरकर्ता (unsatisfied user) म्हणून गणला जाईल आणि असे unsatisfied user असणे सर्च इंजीनला परवडणार नाही (धंदा बसेल हो दुसरे काय, छ्या! मराठी माणसाला धंदा आणि तो बसला असे काही सांगितल्याशिवाय चटकन कळतच नाही). त्यासाठी शोध निकालातली अन्वर्थकता किंवा समर्पकता (relevance) फार महत्वाची असते. सर्च इंजीन्सच्या ह्या relevance चे मूल्यमापन Precision (अचूकता) आणि Recall (?) ह्यांनी केले जाते. ह्या दोन्ही गोष्टी परस्पर पुरक असतात. Precision (अचूकता): म्हणजे सर्च टर्म नुसार शोध निकालात न दाखवायची वेब पेजेस गाळण्याची (Filter) अचूकता Recall (?): म्हणजे सर्च टर्म नुसार शोध निकालात दाखवायची वेब पेजेस निवडण्याची अचूकता आज सर्च इंजीनचे जवळजवळ ८०-८३% मार्केट काबीज करून त्यावर मोनोपॉली असलेल्या गुगलच्या यशाचे 'relevance' हेच मूळ आहे. लॅरी आणि सर्जी ह्या जोडगोळीच्या 'पेजरॅन्क (PageRank)' अल्गोरिदम वर गुगलचा डोलारा उभा आहे. गंमत म्हणजे एकेकाळी त्यांना आणि त्यांच्या ह्याच अल्गोरिदमला कोणीही हिंग लावूनही विचारत नव्हते. शेवटी कंटाळून त्यांनी स्वतःची कंपनी चालू करायचा निर्णय घेतला. :) या खालच्या चित्रात दाखवल्याप्रमाणे एकंदरीत सर्च इंजीन चालते, बरं का रे भाऊ!
(सर्व चित्रे आंतरजालावरून साभार)
वाचने
8146
प्रतिक्रिया
49
प्रतिक्रिया
मस्तच
उत्तम
धन्यवाद.
क्लिष्ट तांत्रिक गोष्टी
आवडेश. प्रश्न : सॉफ्टवेअर
प्रश्न : सॉफ्टवेअर
In reply to आवडेश. प्रश्न : सॉफ्टवेअर by शिल्पा ब
सहीच
माहितीपूर्ण लेख
अतिशय उत्तम माहिती, तीही अगदी
+१
In reply to अतिशय उत्तम माहिती, तीही अगदी by प्रचेतस
सोत्रि
=))
In reply to सोत्रि by श्रावण मोडक
कुणाला?
In reply to =)) by सोत्रि
झकास्स्स्स्स्स्स्स्स्स्स
सः अत्रि
लै भारी
माहितीपूर्ण लेख.......
मस्त!! आवडलं एकदम!!
अजून एक प्रश्न
झैरातीतून
In reply to अजून एक प्रश्न by लॉरी टांगटूंगकर
आवडेश
मस्त लेख.. एक शंका... गूगल
सांभाळून...
In reply to मस्त लेख.. एक शंका... गूगल by भडकमकर मास्तर
अगदी, अगदी
In reply to सांभाळून... by प्रभाकर पेठकर
उत्तर ...
In reply to मस्त लेख.. एक शंका... गूगल by भडकमकर मास्तर
धन्यभाग हमारे....
In reply to उत्तर ... by छोटा डॉन
तांत्रिक उत्तरे
In reply to मस्त लेख.. एक शंका... गूगल by भडकमकर मास्तर
अतिशय उत्तम माहीती. हल्ली
मस्त!
माहीतीपूर्ण
मस्त लेख
सोत्रि
In reply to मस्त लेख by स्मिता.
व्हॅक्युम क्लिनर
In reply to सोत्रि by श्रावण मोडक
+१ टु स्मिता. >>>क्लिष्ट विषय
+१ स्मिता.
झक्कास रे सोत्र्या.
शिकलो
_/\_
सुंदर लेख. आणखीन तप्शील्वार
माहिती आवडली पण आंतरजालावरून
आधी मला वाटायचं सगळी माहीती
द्विरुक्ती
तुस्सी तोप हो!
=))
In reply to तुस्सी तोप हो! by संदीप चित्रे
यासाठी काही करता येते का ?
सुंदर लेख
लई भारी रे सोत्रि !
नक्कीच...
In reply to लई भारी रे सोत्रि ! by जे.पी.मॉर्गन
मस्तं